Deep Learning
딥러닝은 인공신경망의 한 종류로, 대규모의 데이터를 사용하여 복잡한 패턴이나 특징을 자동으로 학습하는 머신러닝 기법이다. 이러한 신경망은 여러 개의 층(layer)으로 구성되어 있어서 "깊은 신경망"이라고 불린다. 각 층은 입력층(input layer), 은닉층(hidden layer), 출력층(output layer)으로 나뉜다.
- 입력층(input layer): 데이터를 받아들이는 층으로, 각각의 특징(feature)을 입력으로 받는다.
- 은닉층(hidden layer): 입력층과 출력층 사이에 위치한 중간 층으로, 데이터의 복잡한 특징을 추출한다.
- 출력층(output layer): 최종적으로 모델의 결과를 출력하는 층으로, 주어진 문제에 맞는 형태로 결과를 출력한다.

먼저 라이브러리들을 모두 임포트 해준다

1.na가 있는지 확인
RowNumber 0
CustomerId 0
Surname 0
CreditScore 0
Geography 0
Gender 0
Age 0
Tenure 0
Balance 0
NumOfProducts 0
HasCrCard 0
IsActiveMember 0
EstimatedSalary 0
Exited 0
dtype: int642.X, Y 데이터 분리
3.원핫 인코딩,레이블 인코딩
array(['France', 'Spain', 'Germany'], dtype=object)array(['Female', 'Male'], dtype=object)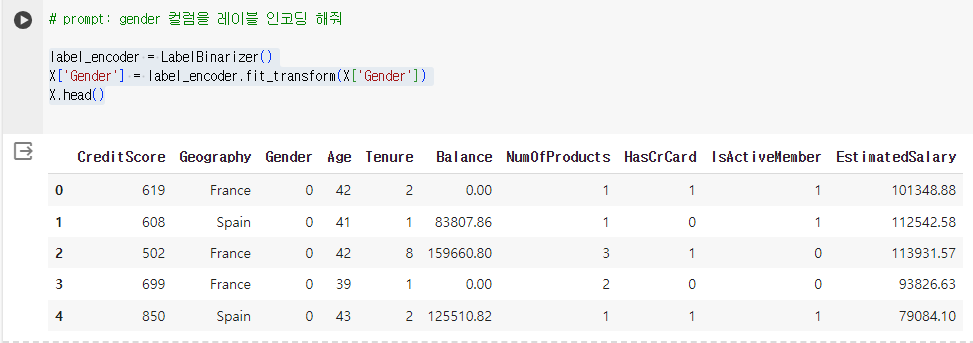
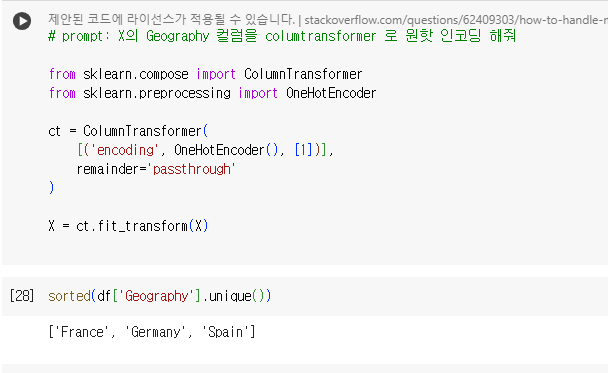
4.Dummy Variable Trap 사용
딥러닝에서는 컬럼하나가 연산에 아주 크게 작용하므로
원 핫 인코딩한 결과에서, 가장 왼쪽의 컬럼은 삭제해도
데이터를 표현하는 데는 아무 문제 없다.
# Fance, Germerny, Spain 3개 컬럼으로 원핫 인코딩 되는데
# 1 0 0
# 0 1 0
# 0 0 1
# 맨 왼쪽 Fance 컬럼을 삭제해도,
# 0 0 => Fance
# 1 0 => Germerny
# 0 1 => Spain
5.피쳐 스케일링 및 트레이닝 및 테스트

6.ANN을 만들어보자(딥러닝)
"Sequential" 모델은 입력층에서 출력층까지 순서대로 층을 쌓아가며 신경망을 구성하는 방법을 제공한다
Dense는 완전 연결층(fully connected layer)을 의미하며, 각 뉴런이 이전 층의 모든 뉴런과 연결되어 있는 층
units는 해당 층의 뉴런 수를 나타냄. 여기서는 8개의 뉴런을 가진 완전 연결층을 추가
activation은 활성화 함수를 지정. 'relu'는 Rectified Linear Unit 함수로, 음수 값을 0으로 만들어 비선형성을 추가
input_shape는 입력 데이터의 형태를 정의. 이 모델에서는 입력 데이터의 차원이 (11,)인 1차원 벡터로 가정
첫 번째 인자인 6은 해당 층의 뉴런 수를 나타냄. 여기서는 6개의 뉴런을 가진 완전 연결층을 추가.
두 번째 인자인 'relu'는 활성화 함수를 지정. 'relu'는 Rectified Linear Unit 함수로, 음수 값을 0으로 만들어 비선형성을 추가
첫 번째 인자인 1은 해당 층의 뉴런 수를 나타냄. 여기서는 하나의 뉴런을 가진 완전 연결층을 추가
두 번째 인자인 'sigmoid'는 활성화 함수를 지정 'sigmoid'는 출력 범위를 0과 1 사이로 제한하여 이진 분류 문제에 적합한 함수

model.summary()
모델의 구조를 요약하여 출력해준다.
7.컴파일(Compile)해준다

Epoch 1/20
750/750 [==============================] - 3s 2ms/step - loss: 0.4781 - accuracy: 0.7949
Epoch 2/20
750/750 [==============================] - 2s 2ms/step - loss: 0.4343 - accuracy: 0.8053
Epoch 3/20
750/750 [==============================] - 1s 2ms/step - loss: 0.4217 - accuracy: 0.8192
Epoch 4/20
750/750 [==============================] - 1s 2ms/step - loss: 0.4121 - accuracy: 0.8271
Epoch 5/20
750/750 [==============================] - 2s 3ms/step - loss: 0.4053 - accuracy: 0.8317
Epoch 6/20
750/750 [==============================] - 3s 3ms/step - loss: 0.3984 - accuracy: 0.8335
Epoch 7/20
750/750 [==============================] - 1s 2ms/step - loss: 0.3905 - accuracy: 0.8368
Epoch 8/20
750/750 [==============================] - 2s 2ms/step - loss: 0.3808 - accuracy: 0.8400
Epoch 9/20
750/750 [==============================] - 1s 2ms/step - loss: 0.3733 - accuracy: 0.8425
Epoch 10/20
750/750 [==============================] - 2s 2ms/step - loss: 0.3660 - accuracy: 0.8475
Epoch 11/20
750/750 [==============================] - 1s 2ms/step - loss: 0.3611 - accuracy: 0.8509
Epoch 12/20
750/750 [==============================] - 1s 2ms/step - loss: 0.3585 - accuracy: 0.8505
Epoch 13/20
750/750 [==============================] - 2s 2ms/step - loss: 0.3557 - accuracy: 0.8539
Epoch 14/20
750/750 [==============================] - 2s 3ms/step - loss: 0.3541 - accuracy: 0.8559
Epoch 15/20
750/750 [==============================] - 2s 3ms/step - loss: 0.3523 - accuracy: 0.8553
Epoch 16/20
750/750 [==============================] - 1s 2ms/step - loss: 0.3513 - accuracy: 0.8565
Epoch 17/20
750/750 [==============================] - 1s 2ms/step - loss: 0.3503 - accuracy: 0.8557
Epoch 18/20
750/750 [==============================] - 1s 2ms/step - loss: 0.3493 - accuracy: 0.8559
Epoch 19/20
750/750 [==============================] - 1s 2ms/step - loss: 0.3485 - accuracy: 0.8573
Epoch 20/20
750/750 [==============================] - 1s 2ms/step - loss: 0.3469 - accuracy: 0.8580
<keras.src.callbacks.History at 0x7cd9d823d030>79/79 [==============================] - 0s 2ms/step - loss: 0.3484 - accuracy: 0.8604
[0.3483799695968628, 0.8604000210762024]
'Deep Learning' 카테고리의 다른 글
| [Deep Learning]딥러닝 CNN 활용하여 이미지 분류 정확도 높이기(Convolution,Pooling) (0) | 2024.04.19 |
|---|---|
| [Deep Learning]딥러닝 ANN으로 이미지API(텐서플로우) 활용하여 이미지 분류하기 (1) | 2024.04.18 |

